
ElevenLabs Models in Rapport - Dec 2024
Information source
Model Summary
ElevenLabs offers several text-to-speech models which can be used within Rapport, each with its own strengths and characteristics:
English v1: The oldest and fastest model, optimized for English. It's reliable but limited in accuracy and flexibility. Best for audiobooks but less suitable for conversational speech.
Multilingual v1 (experimental): Not recommended for general use due to its limitations.
Multilingual v2: A significant improvement over v1, offering better accuracy, naturalness, and language coverage. (model id: eleven_multilingual_v2)
Turbo v2: Optimized for low-latency applications without sacrificing vocal performance. It's English-only and very stable, but slightly less accurate than Multilingual v2.
Turbo v2.5: The latest model, designed for extremely low latency tasks. The model ID is
eleven_turbo_v2_5.Flash: eleven_flash_v2_5. Fast and natural responses. Low latency human like text to speech model id is eleven_flash_V2_5
Eleven Labs Models Details
Eleven Multilingual v2
Category | Details |
|---|---|
Model Name | Eleven Multilingual v2 |
Description | Our most life-like, emotionally rich mode in 29 languages. Best for voice overs, audiobooks, post-production, or any other content creation needs. |
Languages | 29 languages (English, Japanese, Chinese, German, Hindi, French, Korean, Portuguese, Italian, Spanish, Indonesian, Dutch, Turkish, Filipino, Polish, Swedish, Bulgarian, Romanian, Arabic, Czech, Greek, Finnish, Croatian, Malay, Slovak, Danish, Tamil, Ukrainian, Russian) |
Max Characters | 10,000 |
Text to Speech | Yes |
Can be Finetuned | Yes |
Low Latency Optimization | No |
Speaker Boost | Yes |
Additional Features | Style control |
Eleven Turbo v2.5
Category | Details |
|---|---|
Model Name | Eleven Turbo v2.5 |
Description | Our high quality, low latency model in 32 languages. Best for developer use cases where speed matters and you need non-English languages. |
Languages | 32 languages (All languages from Multilingual v2 plus Vietnamese, Norwegian, Hungarian) |
Max Characters | 40,000 |
Text to Speech | Yes |
Can be Finetuned | Yes |
Low Latency Optimization | Yes |
Speaker Boost | No |
Additional Features | Lower cost (0.5x character cost multiplier) |
Eleven Turbo v2
Category | Details |
|---|---|
Model Name | Eleven Turbo v2 |
Description | Our English-only, low latency model. Best for developer use cases where speed matters and you only need English. |
Languages | English only |
Max Characters | 30,000 |
Text to Speech | Yes |
Can be Finetuned | Yes |
Low Latency Optimization | Yes |
Speaker Boost | No |
Additional Features | Lower cost (0.5x character cost multiplier) |
Eleven Flash v2.5
Category | Details |
|---|---|
Model Name | Eleven Flash v2.5 |
Description | Our ultra low latency model in 32 languages. Ideal for conversational use cases. |
Languages | 32 languages (Same as Turbo v2.5) |
Max Characters | 40,000 |
Text to Speech | Yes |
Can be Finetuned | Yes |
Low Latency Optimization | Yes - ultra low latency |
Speaker Boost | No |
Additional Features | Lower cost (0.5x character cost multiplier) |
Eleven Flash v2
Category | Details |
|---|---|
Model Name | Eleven Flash v2 |
Description | Our ultra low latency model in english. Ideal for conversational use cases. |
Languages | English only |
Max Characters | 30,000 |
Text to Speech | Yes |
Can be Finetuned | Yes |
Low Latency Optimization | Yes -Ultra low latency |
Speaker Boost | No |
Additional Features | Lower cost (0.5x character cost multiplier) |
Eleven Multilingual v2 (STS)
Category | Details |
|---|---|
Model Name | Eleven Multilingual v2 (Speech-to-Speech) |
Description | Our cutting-edge, multilingual speech-to-speech model for unparalleled control over content and prosody across languages. |
Languages | 29 languages (Same as Multilingual v2) |
Max Characters | 10,000 |
Text to Speech | No |
Can be Finetuned | Yes |
Low Latency Optimization | No |
Speaker Boost | Yes |
Additional Features | Voice conversion, Style Control |
Eleven English v2 (STS)
Category | Details |
|---|---|
Model Name | Eleven English v2 (Speech-to-Speech) |
Description | Our state-of-the-art speech to speech model for maximum control over content and prosody. |
Languages | English only |
Max Characters | 5,000 |
Text to Speech | No |
Can be Finetuned | No |
Low Latency Optimization | No |
Speaker Boost | Yes |
Additional Features | Voice conversion, Style control |
Eleven Multilingual v1
Category | Details |
|---|---|
Model Name | Eleven Multilingual v1 |
Description | Our first Multilingual model. Now outclassed by Multilingual v2 and Turbo v2.5. |
Languages | 9 languages (English, German, Polish, Spanish, Italian, French, Portuguese, Hindi, Arabic) |
Max Characters | 10,000 |
Text to Speech | Yes |
Can be Finetuned | No |
Low Latency Optimization | No |
Speaker Boost | No |
Additional Features | None |
Eleven English v1
Category | Details |
|---|---|
Model Name | Eleven English v1 |
Description | Our first ever text to speech model. Now outclassed by Multilingual v2 and Turbo v2.5. |
Languages | English only |
Max Characters | 10,000 |
Text to Speech | Yes |
Can be Finetuned | No |
Low Latency Optimization | No |
Speaker Boost | No |
Additional Features | None |
How do I set the ElevenLabs model in Rapport?
Under Project Settings
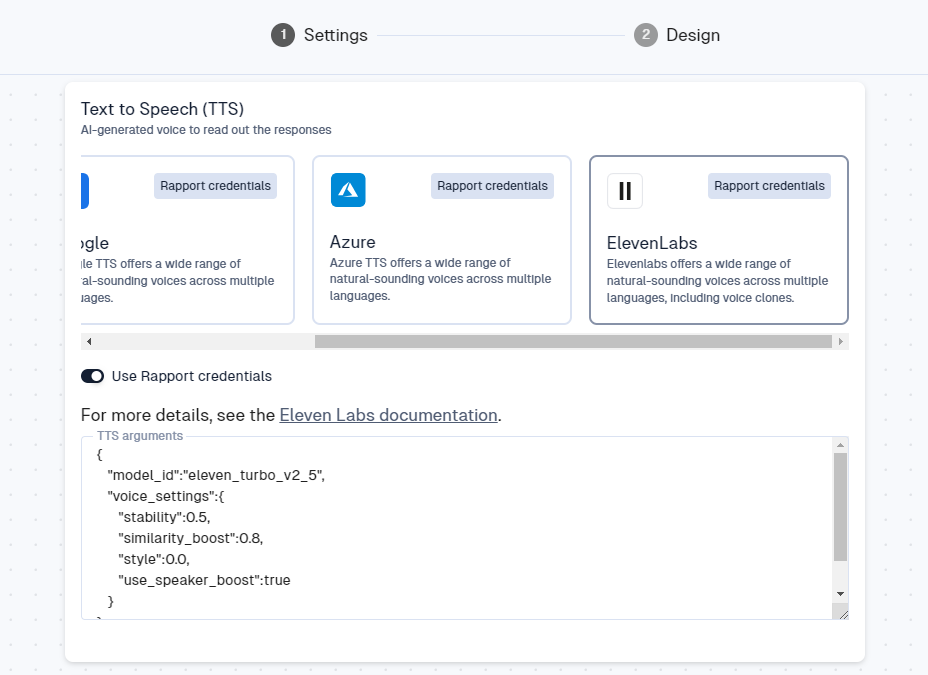
Start by setting the Text to Speech (TTS) option to ElevenLabs. The model can be set in the TTS Args field within the user interface.
To do this, we can enter a small piece of JSON code as shown below. This example uses the model eleven_turbo_v2_5
{
"model_id":"eleven_turbo_v2_5",
"voice_settings":{
"stability":0.5,
"similarity_boost":0.8,
"style":0.0,
"use_speaker_boost":true
}
}In the Rapport user interface (UI) the TTS arguments field is a write field and will validate if an incorrect JSON format has been entered. If you copy the format shown above then everything should be fine. You can however choose to alter the Elevenlabs model to suit your specific requirements.
Next Step. Project Design
In the Project Design select Voice and enter the ElevenLabs Voice ID.
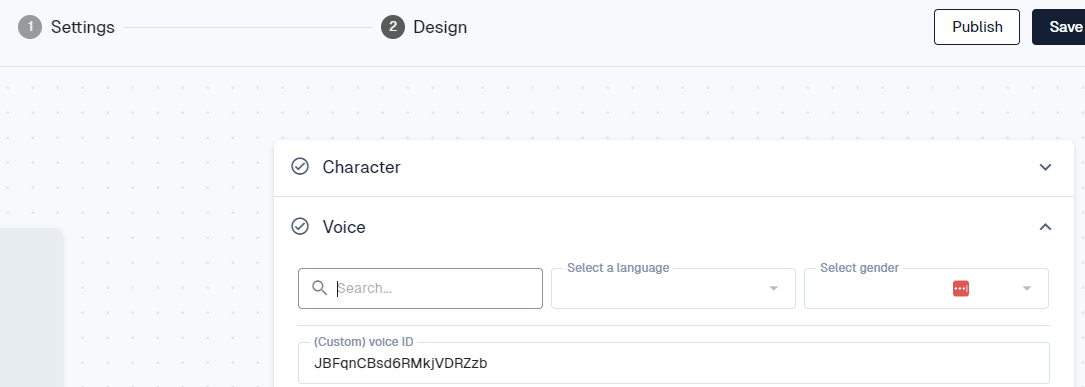
Save your changes
And then click preview and try it out.
Custom Voices
If you are entering a custom voice ID, the voice_id can also be found on Elevenlabs website by selecting a voice on the their interface and clicking on ID, as shown below. This will copy the voice_id which can then be pasted into the field within the Rapport User Interface.
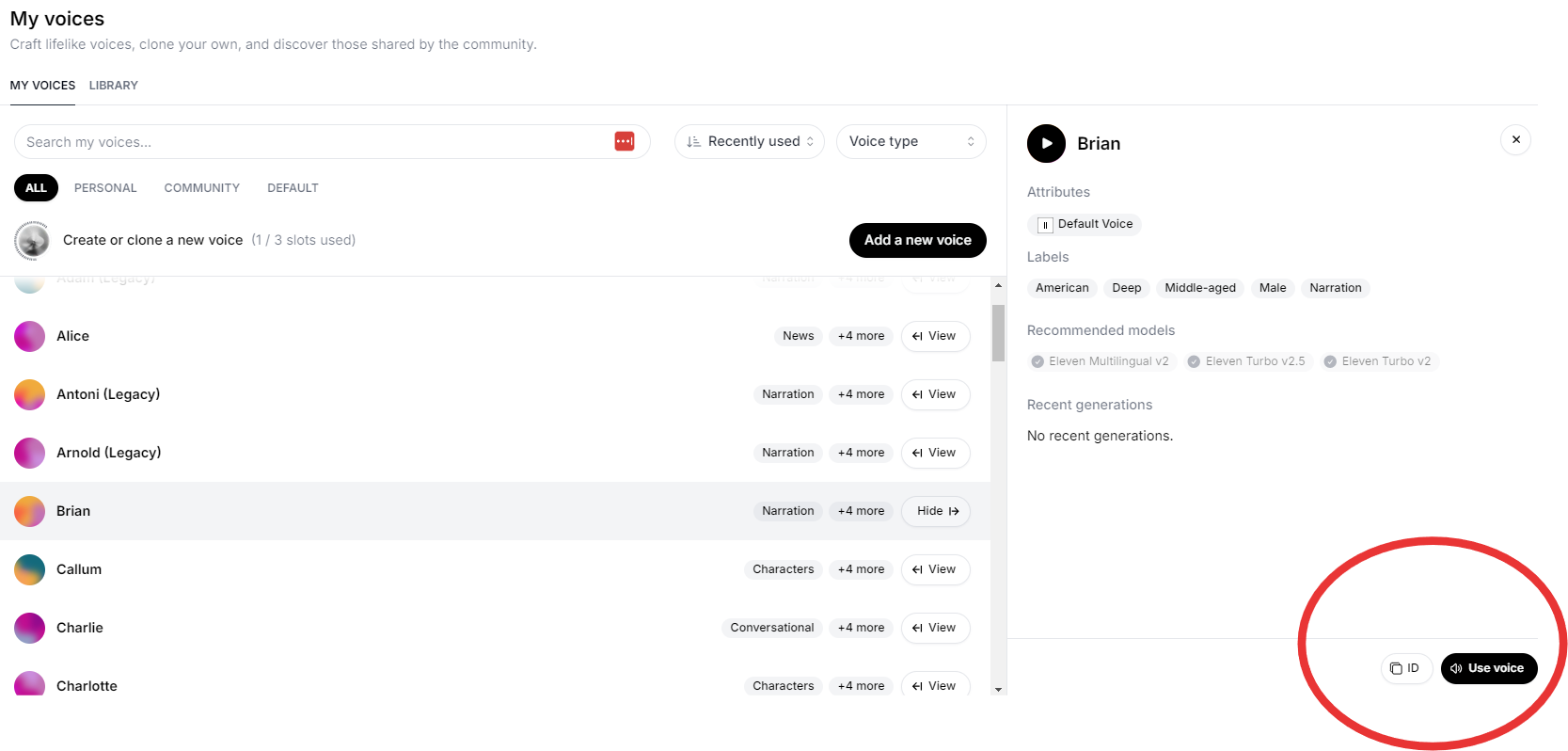
Click here for further information on the ElevenLabs pre-made voices